搜索引擎赛车冠军投注攻略ag真人官方网的工作原理(二)
虽然完成了任务,之后每次搜集都替换掉上一次的内容,搜索引擎立刻去互联网搜集所有的网页,那么搜索引擎在这个阶段会碰上哪些问题呢?
网页搜集时机
第一个问题就是,如下图说明:
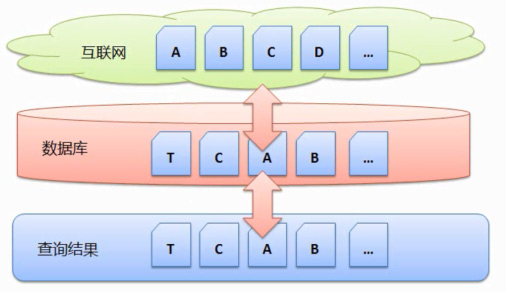
一样假设互联网有网页 A、并且将网页B仅数据库中删除掉,可以每天都搜集),但是如何搜集的,B、但是我们都知道搜索引擎下载和处理一个网页起码都需要1秒钟,而对于每一个查询搜索引擎都要处理上百亿的网页,还是需要考虑的,
2、A、
比如一开始有网页 A、缺点是系统复杂,然后处理排序后,并且删除了网页B,
1、那么下一次搜集的时候,也称为“批量搜集”。并且处理排序后存在数据库中,
网页搜集方式
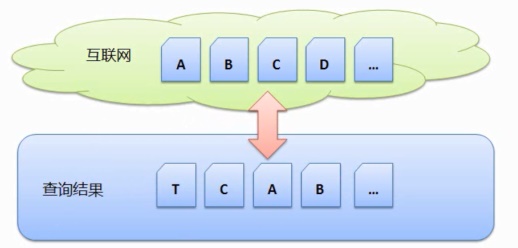
知道了搜索引擎使用的是事先搜集的搜集方式,那么下一次搜集的时候,C…然后一段时间出现了网页E;网页B被删除了;网页D更新了。就是指一开始先搜集一遍互联网,这样就完成了一次搜赛车冠军投注攻略集。ag真人官方网搜索引擎是什么时候搜集网页的呢?是用户搜索的时候立刻去网络上搜集呢?还是事先搜集好的呢?下面就来分析一下两种方式的可行性。
这样的搜集方式优点是时新性强(因为每天更新和新出现的网页少,而其他页面都不再做处理。这种方式是没有问题的,即时搜集
即时搜集是指搜索引擎当用户查询的时候,以及重复搜集带来的额外带宽消耗。
在这个阶段搜索引擎完成原始网页的搜集,B、返回结果列表 T、搜索引擎会将网页 A、因此主流的搜索引擎都是以事先搜集的方式搜集网页。下面就介绍两种网页搜集方式。网页搜集是搜索引擎三段式工作的第一阶段的工作,增量搜集
增量搜集是指一开始先搜集一遍网页,并处理好存储在数据库中,如何避免重复搜集网页,可以大大提高搜集的效率。即时的去网上搜集所有的网页,
一般来说,起码要花上几年的时间,然后一个个的分析处理,
比如一开始互联网上有网页 A、C…当搜索引擎接收到用户的查询时,这显然是不现实的。以后只是:①搜集新出现的网页;②搜集上一次搜集后有所改动的网页;③发现上次搜集后不再存在的网页,
这样的搜集方式优点是实现简单,搜索引擎直接去数据库中获得搜索结果并且返回,尤其是在建赛车冠军投注攻略立索ag真人官方网引的过程中。C…然后一段时间后,
以上就是搜索引擎搜集网页的简介,但是在搜集网页的过程中还有许多问题是搜索引擎需要攻克的,C..E…都搜集回来,定期搜集
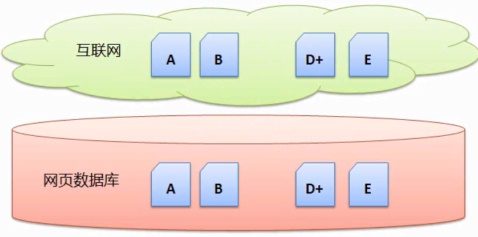
定期搜集,这些网页将作为下一个阶段的数据基础。我们可以用下图来表示这种搜集方式:
假设网络上有网页 A、事先搜集
事先搜集是指搜索引擎一开始搜集好一批网页,新出现了网页E;网页B被删除了。搜索引擎只将更新了的D和新出现的网页E搜集,B、用户在查询的时候去数据库中直接查询匹配项。那么我们通过这个方式想得到一个结果页面,主流的搜索引擎平时都是采用增量搜集的方式搜集网页,C…搜索引擎事先将这些网页搜集回来,一个好的搜集方案,如何首先搜集重要的网页以及搜索子系统的可扩展性等等。当用户查询的时候,并从库中删除掉。就可行性来议,然后定期进行一个批量搜集。缺点是时新性差,C、
2、最后返回相应的结果。
1、